

Hace unos meses, cuando empecé a ver que se hablaba de llms.txt en todos lados, hice lo que cualquiera en este rubro: subí uno a un par de proyectos sin pensarlo mucho. Diez minutos, un archivo de texto en la raíz del dominio y listo.
La lógica parecía sólida: si los modelos de lenguaje van a leer mi sitio para responder preguntas, ¿por qué no darles un resumen ordenado en vez de dejar que se las arreglen solos con el HTML? El problema es que esa lógica, que suena impecable en una reunión, no tiene mucho respaldo cuando vas a buscar los números.
Ahrefs analizó hace poco los registros de servidor de 137.000 dominios y encontró algo que te baja bastante a tierra: el 28% de esos sitios ya publica un archivo llms.txt, pero de ese grupo, solo el 3% recibió alguna consulta real en todo un mes. El resto, silencio absoluto. Y como justo apareció ese estudio, me pareció el momento de sentarme a escribir esto con calma: qué es realmente este archivo, por qué generó tanto ruido y qué dice la evidencia sobre si vale la pena el esfuerzo.
Empecemos por lo básico: ¿qué es un archivo llms.txt?
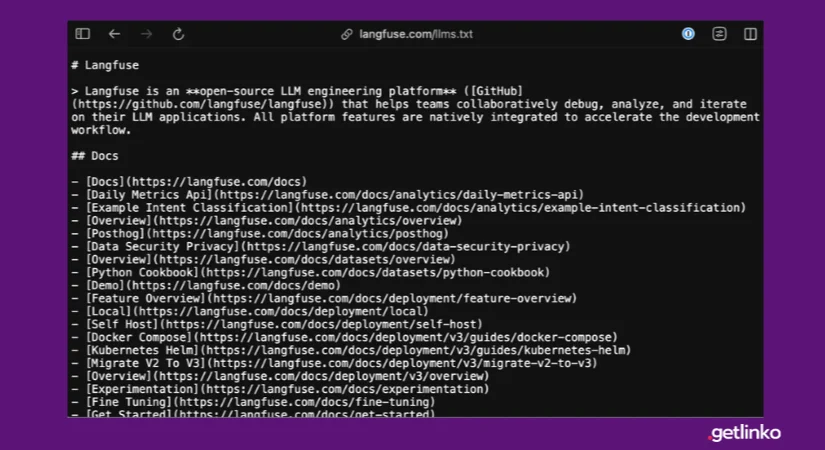
Un llms.txt es, en esencia, un archivo de texto plano escrito en markdown que se coloca en la raíz de un sitio web, igual que el robots.txt de toda la vida. La idea original es bastante simple: en lugar de que un modelo de lenguaje tenga que rastrear todo tu sitio, lidiando con menús, banners de cookies y código que no le aporta nada, le dejás un resumen directo de qué es tu proyecto y cuáles son las páginas que realmente importan.
La propuesta la lanzó Jeremy Howard, cofundador de Answer.AI y fast.ai, en 2024. Y vale la pena aclarar dos cosas que se confunden seguido:
- No es lo mismo que publicar versiones en markdown de cada página de tu sitio: esa es otra práctica, con sus propios problemas, y no tiene nada que ver con el archivo índice del que estamos hablando.
- A pesar del nombre, no funciona como una directiva al estilo robots.txt: no bloquea nada, no controla el rastreo de nadie. Es solamente información, a disposición de quien quiera leerla.
Una forma de entenderlo, que me sirvió bastante para explicárselo a clientes que recién se enteraban del tema: pensá en tu sitio como un local de comida. El robots.txt es el que le dice al mozo qué mesas puede ofrecer y a cuáles no puede ni acercarse. El sitemap es la carta completa, con cada plato listado para que el que quiera revisar todo lo pueda hacer. El llms.txt sería más parecido a esa hojita corta donde el chef recomienda dos o tres platos: no reemplaza la carta, simplemente intenta ahorrarle trabajo a quien tiene poco tiempo para leer todo.
Suena prolijo. El tema es que “sonar prolijo” y “funcionar en la práctica” son dos cosas distintas, y ahí es donde se pone interesante.
Por qué el archivo generó tanto revuelo
La adopción no salió de la nada. Empresas como Anthropic, Perplexity y Eleven Labs lo incorporaron en sus propios sitios, y eso le dio cierta legitimidad al asunto. Si compañías que literalmente construyen modelos de lenguaje lo están usando, la conclusión rápida (y entiendo por qué tantos la sacaron) fue: “esto debe servir, sigamos su ejemplo”.
A esto se le sumó el argumento de las alucinaciones. Cuando un bot de OpenAI o de Anthropic entra a una página para sacar información, tiene que procesar menús, avisos legales, scripts y demás ruido. Eso consume recursos, y en algunos casos puede llevar a que el modelo termine inventando datos sobre una empresa porque no entendió bien el contexto. El llms.txt, en teoría, evita ese problema dándole al modelo un resumen limpio escrito por el propio dueño del sitio.
Es un argumento razonable. El problema, como casi siempre en SEO, es que “razonable” no es lo mismo que “comprobado”, y bastante de lo que se difundió sobre este archivo se basó en especulación más que en datos reales de tráfico.
La pelea interna de Google (que dice más de lo que parece)
Esta parte me resultó particularmente reveladora, porque expone algo que pasa seguido en el mundo SEO: distintos equipos dentro de la misma empresa, dando señales contradictorias.
Por un lado, el equipo de Google Search fue clarísimo: su guía sobre optimización para funciones de IA generativa, en una sección que literalmente se llama “desmintiendo mitos”, afirma que los archivos legibles por máquinas como llms.txt no son necesarios para aparecer en la búsqueda de IA generativa. John Mueller fue todavía más directo cuando le insistieron con el tema: dijo que el archivo “no está hecho para la búsqueda”, que es más bien una solución temporal pensada para ahorrar tokens en herramientas de codificación que analizan documentación técnica, y que los sitios que no son para desarrolladores no tendrían por qué preocuparse.
Por otro lado, días después de esa guía, el equipo de Chrome agregó una comprobación de llms.txt dentro de las auditorías experimentales de navegación agéntica de Lighthouse. O sea: mientras un equipo de Google te dice que lo ignores, otro equipo de la misma empresa lo está evaluando como una práctica relevante para el futuro de los agentes de IA que van a navegar la web en nombre de los usuarios.
¿Quién tiene razón?
Mi lectura, después de leer bastante sobre el tema, es que probablemente los dos. Mueller tiene razón en que hoy, para la búsqueda tradicional y para la mayoría de las plataformas de IA conversacional, el archivo no mueve la aguja. Pero el equipo de Chrome también tiene un punto: si el futuro de la navegación incluye agentes que actúan por nosotros, dejarles un mapa claro del sitio no es una mala idea a largo plazo. El tema es que “a largo plazo” y “hoy, en mayo de 2026” son momentos distintos, y la mayoría de los sitios que se subieron a esta ola lo hicieron pensando en el corto plazo.
Cómo se construye un archivo llms.txt (la parte técnica, resumida)

Si después de todo esto decidís probarlo igual, y hay razones legítimas para hacerlo, ya lo vamos a ver, la estructura es bastante accesible. El archivo se sube como texto plano a la raíz del dominio, exactamente en el mismo lugar donde vive el robots.txt. Cualquier panel de hosting con administrador de archivos te permite crearlo: entrás a la carpeta pública de tu sitio, creás un archivo de texto, lo nombrás llms.txt, y listo. Después lo podés visitar directamente escribiendo tudominio.com/llms.txt en el navegador para confirmar que se ve bien.
La sintaxis usa markdown simple:
- Un solo hashtag (#) funciona como el título principal del documento, generalmente el nombre del sitio o del proyecto.
- Los hashtags dobles (##) actúan como subtítulos, separando secciones (por ejemplo, “Documentación”, “Guías”, “Productos”).
- Los enlaces siguen el formato típico de markdown: la descripción va entre corchetes, seguida de la URL entre paréntesis, y opcionalmente una breve explicación después de dos puntos.
- Las listas se arman con guiones o asteriscos, igual que en cualquier archivo markdown.
No hay un estándar cerrado sobre cuántos enlaces incluir, pero acá metería una opinión propia bastante fuerte: menos es más. Los modelos tienen límites de tokens, así que si volcás ahí cada artículo que publicaste en los últimos cinco años, lo más probable es que el rastreador ignore buena parte del archivo o lo descarte directamente. Tiene más sentido curar de verdad: elegir las cinco o diez páginas que mejor representan lo que hace tu sitio, y dejar afuera todo lo que no aporta valor por sí solo. Páginas de login, checkout, políticas de privacidad o landings cargadas de JavaScript no tienen nada que hacer ahí.
Otra cosa que aprendí probando esto en distintos proyectos: revisá que los enlaces funcionen. Un archivo con URLs rotas no solo es inútil, sino que genera el efecto contrario al que buscas, porque confunde a cualquier sistema que intente seguir esos enlaces.
Lo que de verdad cambió mi forma de ver el tema: los datos de Ahrefs
Hasta acá, todo lo que vimos es teoría, intuición y casos sueltos. Lo que le faltaba a esta discusión era un estudio con volumen real, y eso es justo lo que aportó Ahrefs cuando analizó los registros de servidor y el tráfico de 137.000 dominios usando sus herramientas de Web Analytics y Bot Analytics. Y la verdad, los resultados me hicieron repensar bastante mi propio entusiasmo inicial con el tema.
- Adopción: El 28% de esos dominios publica un archivo llms.txt. Es una cifra alta para un estándar que ninguna plataforma de IA se comprometió formalmente a leer, y que probablemente esté inflada porque los usuarios de herramientas como Ahrefs suelen ser más técnicos y estar más al día con tendencias de SEO que el promedio de la web. Aun así, más de uno de cada cuatro sitios decidió subirse a la ola.
- El dato que más me sorprendió: Del total de archivos válidos detectados, el 97% no recibió absolutamente ninguna petición en mayo de 2026. Ni de bots, ni de personas. Nada. Publicaste el archivo, y con altísima probabilidad, nadie lo va a tocar nunca. Leyendo esto pensé en los proyectos donde yo mismo lo subí sin revisar después si alguien lo estaba leyendo. Spoiler: fui a chequear y la experiencia no fue muy distinta a la del estudio.
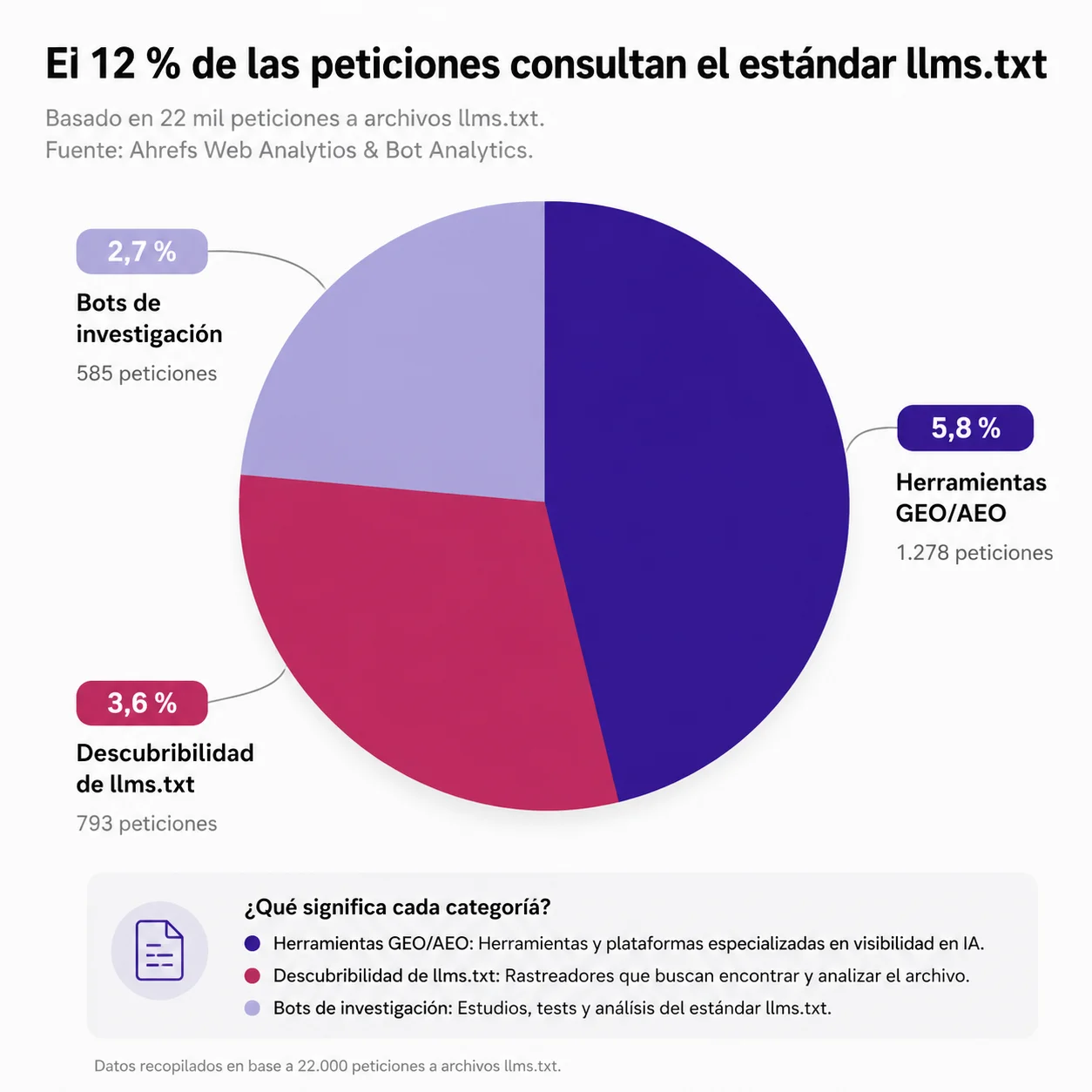
- De ese 3% que sí recibe tráfico: el 96% son bots. Los humanos representan apenas el 4% restante, y buena parte de ellos son probablemente colegas de SEO compartiendo el enlace en aplicaciones de chat, que después generan vistas previas automáticas. De hecho, el bot de vistas previas de Slack rastreó más archivos llms.txt que el bot de Perplexity, uno de los motores de búsqueda de IA que este archivo supuestamente debía ayudar a posicionar. Esa comparación sola dice bastante sobre el nivel de interés real que están generando estos archivos del lado de la IA conversacional.
- Dentro de ese tráfico de bots: El 77% no tiene nada que ver con herramientas de inteligencia artificial. Son rastreadores de auditoría SEO, bots sin identificar, crawlers generales y herramientas de perfilado tecnológico. Cuando agrupás todas las categorías relacionadas con IA (entrenamiento, agentes, asistentes y bots de recuperación), juntas llegan al 19,5% de las peticiones. Es la porción individual más grande, sí, pero está lejos de ser mayoría.
- Quién lidera dentro del 19,5%: Lo que más me llamó la atención es quién lidera: no son los buscadores de IA conversacional que la mayoría de la gente tiene en la cabeza cuando piensa en visibilidad en IA. El primer lugar es de GPTBot, un rastreador de entrenamiento. El segundo es Claude Code, el agente de programación de Anthropic. Los bots de recuperación que realmente alimentan respuestas en tiempo real, los que uno imagina respondiendo preguntas de usuarios en ChatGPT o Perplexity, apenas representan el 1,1% del total. Esto coincide bastante con lo que decía Mueller: el archivo parece tener más sentido como referencia para agentes de programación que como palanca de visibilidad en buscadores de IA.
- El ecosistema del meta-análisis: Otro dato que vale la pena remarcar: hay todo un ecosistema de herramientas dedicadas exclusivamente a auditar, puntuar y catalogar archivos llms.txt, que en conjunto representan el 12% de las peticiones totales. O sea, hay más actividad estudiando el fenómeno que plataformas de IA consumiéndolo de verdad para responder consultas. Eso, sinceramente, me hizo bastante gracia, porque es un patrón clásico del mundo SEO: convertir cualquier especulación en una industria entera antes de confirmar si la especulación tenía fundamento.
- El mito del “por si acaso”: Por último, un dato que cierra bastante el debate sobre “publicarlo por si acaso”: ningún bot de IA fue a buscar archivos llms.txt en sitios donde el archivo no existía. Cero peticiones. Las únicas visitas a rutas inexistentes vinieron de personas escribiendo la URL manualmente en el navegador, casi seguro profesionales de SEO revisando a la competencia. Esto tira por la borda la idea de que un sitio sin llms.txt está “perdiendo una oportunidad” frente a algún rastreador de IA que anda buscando el archivo de forma proactiva. No existe tal rastreador. Los bots llegan al archivo cuando algo, un enlace, un índice, una instrucción explícita les indica que está ahí, no por iniciativa propia.
Entonces, ¿vale la pena crearlo o no?
Después de leer todo esto, mi postura cambió de “dale, lo subo en todos lados porque no cuesta nada” a algo más calculado. Y creo que la pregunta correcta no es “¿sirve o no sirve?”, sino “¿para quién y para qué caso puntual?”
Si tu objetivo es aparecer en respuestas de ChatGPT, conseguir menciones en Perplexity o entrar en una AI Overview, el archivo hoy es básicamente decorativo. Los bots de recuperación de IA apenas lo rastrean, ningún sistema va a buscar uno que no publicaste, y la tasa base de “cero lectores” es del 97%. Si estás invirtiendo tiempo en esto pensando que va a mover tu visibilidad en buscadores de IA, conviene redirigir ese esfuerzo a otro lado.
Ahora, si tus clientes o usuarios interactúan con agentes de programación, pensá en equipos de desarrollo que usan asistentes de IA para integrar tu API o entender tu documentación, ahí el archivo sí tiene una chance real de ser leído y de ahorrarle tiempo a quien lo consulta. Esto coincide con algo que vengo viendo en proyectos más técnicos: la documentación para developers es, hasta ahora, el terreno donde este formato tiene más sentido práctico.
También hay un argumento de “preparación a futuro” que no me parece descartable del todo. Si la navegación agéntica termina mediando buena parte de la búsqueda de agentes que actúan en nombre del usuario, en lugar de bots de recuperación que rastrean páginas directamente, el llms.txt podría empezar a pesar más en ese escenario. Pero eso es una apuesta sobre cómo va a evolucionar la web, no una garantía.
Y hay un punto que casi nadie menciona cuando habla de este archivo, y que a mí personalmente me preocupa más que la falta de tráfico: el riesgo de seguridad. Los agentes están diseñados para confiar en lo que dice un llms.txt, y ya hay quien está estudiando sistemáticamente este archivo como una superficie de inyección de prompts. Un archivo desactualizado, o directamente comprometido por alguien con acceso al servidor, puede terminar engañando a cualquier agente que confíe en su contenido. Si vas a publicarlo, tiene sentido tratarlo con la misma seriedad que tratarías cualquier archivo de configuración expuesto: control de versiones, restricciones de quién puede editarlo y revisión de lo que cualquier plataforma autogénere en tu nombre.
Mi veredicto, con los pies en la tierra
Si me preguntás hoy si vale la pena correr a crear uno, mi respuesta es: depende de cuánto te cuesta hacerlo y qué esperás a cambio. Publicarlo es barato, no rompe nada y cada vez más constructores de sitios lo van a generar automáticamente sin que el dueño tenga que mover un dedo. En ese sentido, no hay mucho que perder.
Lo que sí me parece un error es invertir tiempo de estrategia pensando que este archivo va a reemplazar o complementar de forma significativa el trabajo real de visibilidad: contenido bien estructurado, autoridad de dominio, enlaces de calidad, experiencia de usuario. Esas variables siguen siendo las que de verdad mueven la aguja, tanto en búsqueda tradicional como en lo que terminen siendo los motores de IA del futuro. El llms.txt, por ahora, es un complemento menor, no una estrategia.
Si decidís probarlo, estos son los pasos que yo seguiría:
- Antes de invertir más tiempo, revisá tus propios registros de servidor para ver si algo está pidiendo el archivo. La tasa base es del 97% de cero lectores, así que no te sorprendas si el resultado es silencio total.
- Dejá que la plataforma donde tenés el sitio lo genere por vos si ya ofrece esa opción. Cada vez más constructores web lo están incorporando de forma nativa, así que en poco tiempo puede ser tan estándar como tener un sitemap, sin que implique una decisión estratégica de tu parte.
- Si tu sitio tiene documentación técnica o atiende a un público que usa herramientas de programación con IA, enlaza el archivo desde el HTML y desde la propia documentación. Los agentes lo rastrean cuando algo les indica que existe, no por instinto propio.
- Tratalo como código, no como un texto suelto: control de versiones, acceso restringido, y revisión periódica de su contenido.
Quedan preguntas abiertas que todavía no tienen una respuesta clara, como si los agentes que sí leen el archivo después sigan los enlaces que contiene, o si el interés de las herramientas de programación se concentra específicamente en rutas de documentación. Es un terreno que recién se está empezando a medir en serio.
Mi conclusión personal, después de meterme de lleno en esto: probablemente estemos viendo, al mismo tiempo, el comienzo de un estándar real para un caso de uso bastante específico (documentación técnica y agentes de programación), y la enésima demostración de que el mundo del SEO puede convertir cualquier especulación en una tendencia antes de tener evidencia firme de que funciona. No es que el archivo sea inútil. Es que el hype le quedó bastante grande a lo que los datos, hasta ahora, pueden respaldar.
FAQs
1) ¿Qué es un archivo llms.txt?
Es un archivo de texto plano en formato Markdown ubicado en la raíz de un dominio. Su propósito original es ofrecer a los modelos de lenguaje un resumen limpio y directo de la estructura y las páginas más importantes de un sitio web, evitando que tengan que procesar elementos innecesarios del código HTML, como menús o banners.
2) ¿Funciona el archivo llms.txt igual que un archivo robots.txt?
No. A diferencia del archivo robots.txt, el llms.txt No es una directiva de rastreo; es decir, no bloquea el acceso a los bots ni controla sus acciones. Su función es puramente informativa, actuando como una recomendación de contenido para los sistemas que decidan leerlo.
3) ¿Es obligatorio tener un archivo llms.txt para aparecer en las búsquedas de IA de Google?
No, según el equipo de Google Search, no es necesario. En sus guías oficiales aclaran que este tipo de archivos no se requieren para aparecer en las funciones de IA generativa, sin embargo el equipo de Chrome agregó una comprobación de llms.txt dentro de las auditorías experimentales.
4) ¿Qué porcentaje de sitios web que usan llms.txt reciben tráfico real en este archivo?
De acuerdo con un estudio de Ahrefs que analizó 137.000 dominios, aunque el 28% de los sitios ya publica un archivo llms.txt, solo el 3% recibió alguna consulta real en todo un mes. El 97% restante no registró ninguna petición.
5) ¿Quiénes son los principales visitantes de los archivos llms.txt en la actualidad?
El tráfico es predominantemente automatizado: el 96% de las visitas proviene de bots y solo el 4% de humanos. Dentro del tráfico de bots, el 77% corresponde a rastreadores de auditoría SEO o herramientas tecnológicas generales, mientras que las herramientas de IA representan el 19,5%, lideradas por rastreadores de entrenamiento (GPTBot) y agentes de desarrollo (Claude Code).
6) ¿Qué páginas se deben incluir al configurar un archivo llms.txt?
Se recomienda incluir una selección curada de las 5 o 10 páginas más importantes que mejor representen el valor del sitio, como la documentación técnica o guías principales. Se deben dejar fuera las páginas de inicio de login,carritos de compra, checkout, políticas de privacidad o páginas con exceso de JavaScript.
7) ¿Existe algún riesgo de seguridad asociado al archivo llms.txt?
Sí. Los agentes de Inteligencia Artificial están diseñados para confiar en la información de este archivo, lo que lo convierte en una superficie potencial para ataques de inyección de prompts. Por ello, se debe tratar con la misma seriedad que un archivo de configuración expuesto, implementando control de versiones y revisiones periódicas.




